8.06. Машинное обучение
Что такое машинное обучение?
Машинное обучение (Machine Learning, ML) — это раздел искусственного интеллекта, который фокусируется на разработке алгоритмов, способных обучаться на данных. Вместо явного программирования поведения системы, она сама находит закономерности в данных и строит модели для прогнозирования или классификации.
Три основных типа машинного обучения:
- Обучение с учителем (supervised learning) - модель обучается на парах входных данных и целевых значений.
- Обучение без учителя (unsupervised learning) - модель ищет скрытые паттерны в данных без целевых меток.
- Обучение с подкреплением (reinforcement learning) - модель учится на основе взаимодействия с окружающей средой и получения наград.
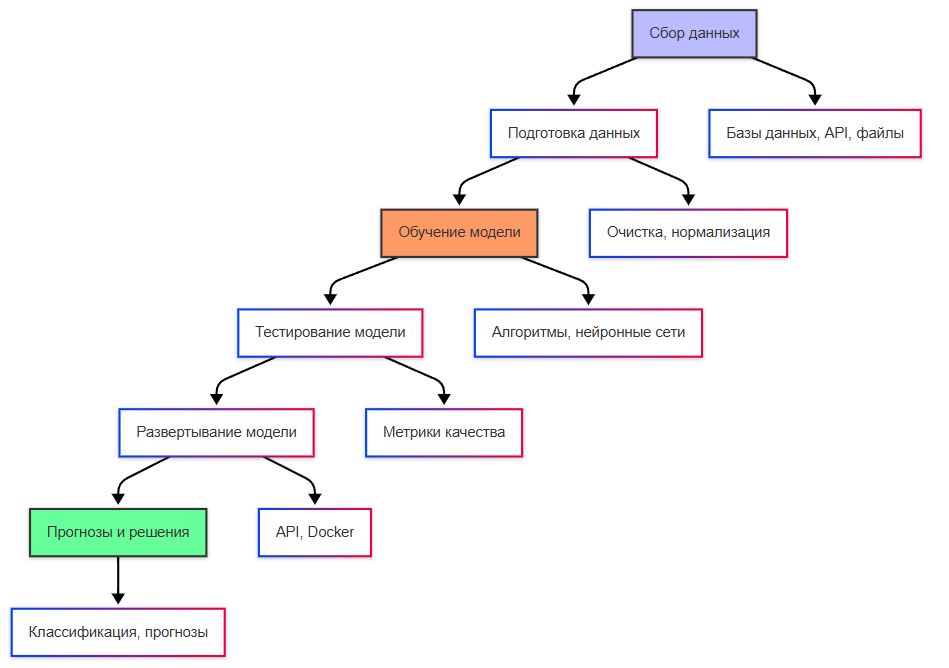
Алгоритмы обучения на основе данных — это методы, которые позволяют системам ИИ строить модели, основываясь на анализе большого количества информации. Эти алгоритмы автоматически находят зависимости, закономерности и корреляции в данных.
- Свёрточные слои применяют фильтры для выделения признаков.
- Пулинговые слои уменьшают размерность данных.
- Полносвязные слои выполняют классификацию.
Глубокое обучение (Deep Learning) — это подраздел машинного обучения, основанный на использовании глубоких нейронных сетей (сетей с большим количеством слоёв). Эти сети способны автоматически извлекать сложные паттерны из данных, что делает их особенно эффективными для работы с большими объёмами неструктурированной информации. Сети состоят из множества скрытых слоёв, каждый из которых извлекает всё более абстрактные признаки. В отличие от традиционного машинного обучения, где признаки нужно вручную задавать, глубокое обучение самостоятельно находит важные признаки. Требует мощных вычислительных ресурсов (например, GPU или TPU).
Глубокое обучение используется в CNN, RNN, LSTM и трансформерах.
Датасет (dataset) — это набор данных, который используется для обучения, тестирования и оценки моделей машинного обучения или искусственного интеллекта. Датасеты содержат информацию, необходимую для решения конкретной задачи: изображения, тексты, числовые данные, аудио и т.д.
Датасеты могут быть обучающими, валидационными, тестовыми, могут быть структурированными или неструктурированными - всё зависит от самих данных.
Есть готовые датасеты, которые предоставляются для обучения моделей - MNIST (набор рукописных цифр) для классификации цифр, CIFAR-10 (набор цветных изображений), IMDb (для анализа тональности текста из отзывов по фильмам), Wikipedia Text Corpus (большая коллекция текстов), ImageNet (коллекция миллионов изображений), COCO (изображения с разметкой объектов), и многие другие.
Собственный датасет — это просто набор данных, который собирают буквально - ручками. Нужно понять задачу и собрать данные - из открытых источников, API, по сайтам.
Данные важно разделять по типам - сложно организовать обучение с разными типами, беспорядочно перемешанными. При обучении, главное - понять, какие бывают типы (табличные, текст, изображения, временные ряды) и откуда их брать (встроенные датасеты, Kaggle, ETL-процессы).
Обучение нейросетей — это процесс настройки весов и параметров сети для выполнения конкретной задачи.
Это автоматическое извлечение знаний из данных без явного программирования правил.
Computer Vision
Распознавание лиц, объектов, OCR, медицинская диагностика.
NLP (обработка текста)
Чат-боты, переводчики, суммаризация, анализ тональности
Рекомендательные системы
Netflix, Spotify, Amazon, TikTok — подбор контента.
Аналитика и прогнозы
Прогноз спроса, отказов оборудования, цен, нагрузки на серверы.
Кибербезопасность
Обнаружение аномалий, фишинга, вредоносного ПО.
Генерация контента
GPT, Stable Diffusion, музыка, код, видео.
Робототехника и автопилоты
Восприятие среды, принятие решений, управление.
DevOps / SRE
Аномалии в логах, прогнозирование инцидентов, оптимизация ресурсов.
Как происходит обучение? Градиентный спуск и обратное распространение
1. Функция потерь (Loss Function)
Измеряет, насколько сеть ошиблась.
MSE — для регрессии.
Cross-Entropy — для классификации.
Custom loss — для специфичных задач.
2. Обратное распространение ошибки (Backpropagation)
Алгоритм вычисления градиента функции потерь по каждому весу.
Использует цепное правило дифференцирования.
Реализован автоматически в PyTorch / TensorFlow (autograd).
3. Градиентный спуск (Gradient Descent)
Обновление весов в направлении, противоположном градиенту
4. Оптимизаторы
SGD — стохастический градиентный спуск.
Adam — адаптивный, с моментами (самый популярный).
RMSprop, Adagrad, AdamW — для разных случаев.
- Подготовка данных. Данные делятся на три набора:
- Обучающий набор используется для обучения модели.
- Валидационный набор проверяет качество модели во время обучения.
- Тестовый набор оценивает модель после завершения обучения.
Здесь происходит сбор, нормализация, очистка от шума. Для некоторых задач (например, компьютерного зрения) требуется дополнительная обработка: изменение размера изображений, аугментация данных.
- Инициализация весов. Веса нейронов инициализируются случайными значениями, что необходимо для того, чтобы модель могла начать обучение.
- Прямое распространение (Forward Propagation). Входные данные проходят через все слои сети, пока не достигнут выходного слоя. На каждом шаге применяются функции активации (например, ReLU, Sigmoid). Результат сравнивается с целевыми значениями для вычисления ошибки.
- Вычисление ошибки. Ошибка измеряется с помощью функции потерь (loss function):
- MSE (Mean Squared Error) для задач регрессии.
- Cross-Entropy Loss для задач классификации.
Чем меньше ошибка, тем лучше модель соответствует данным.
- Обратное распространение ошибки (Backpropagation). Ошибка распространяется обратно через сеть, корректируя веса. Для этого используется градиентный спуск (gradient descent). Градиентный спуск минимизирует функцию потерь, изменяя веса в направлении, противоположном градиенту.
- Оптимизация. Для улучшения сходимости используются различные алгоритмы оптимизации:
- SGD (Stochastic Gradient Descent) базовый метод.
- Adam более современный и эффективный метод.
- Оценка модели. После завершения обучения модель тестируется на тестовом наборе данных. Оцениваются метрики, такие как точность (accuracy), F1-score, ROC-AUC. Если модель показывает плохие результаты, её можно дообучить или перестроить.
Метрики качества: Accuracy, Precision, Recall, F1-score — что они означают и когда какую использовать.
ROC-кривая и AUC: Визуальный и численный способ оценить качество классификатора.
Матрица ошибок (Confusion Matrix): Наглядный способ увидеть, где модель ошибается (False Positive, False Negative).
Кросс-валидация (k-fold): Метод для более надежной оценки модели, особенно на небольших датасетах.
Разведочный анализ данных (EDA — Exploratory Data Analysis)
Удаление дубликатов.
Обработка пропусков (NaN)
Когда удалять признак, когда заполнять средним/медианой/модой.
Обнаружение аномалий (выбросов)
Визуальные методы (boxplot) и статистические (квантили).
Описательная статистика: Среднее, минимум, максимум, распределение.
Важность признаков: Как понять, какие факторы влияют на результат (например, с помощью Chi-squared test).
Многомерный анализ: Визуализация взаимосвязей между признаками (pairplot в Seaborn).
Понижение размерности (PCA): Зачем и как сокращать количество признаков.
Преобразование данных: Стандартизация и нормализация — зачем приводить данные к одному масштабу.
Пересэмплирование (SMOTE): Как бороться с дисбалансом классов в задачах классификации.
Глубокое обучение (DL) как подмножество ML: Объяснить разницу между ML и DL, ввести понятие нейронных сетей.
Многослойный перцептрон (MLP): Как простейший пример нейронной сети, его структура (входной, скрытые, выходной слои) и применение.
Инструменты и экосистема: Упомянуть ключевые библиотеки Python (Pandas, Scikit-learn, Seaborn, Matplotlib, Plotly) и платформы (Google Colab для DL).
PyTorch
Гибкий, популярен в исследованиях, отличная отладка.
TensorFlow
Мощный для продакшена, Keras — удобный высокоуровневый API.
Keras
Упрощённый API поверх TF (или standalone).
JAX
Для исследований, автоматическое дифференцирование + XLA.
Hugging Face
Библиотека трансформеров и предобученных моделей (NLP, CV).
ONNX
Универсальный формат для обмена моделями между фреймворками.
Weights & Biases / MLflow
Трекинг экспериментов, логирование, визуализация.